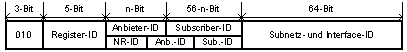|
Grundlagen Computernetze
Prof. Jürgen Plate |
8 TCP/IP
Die Protokolle der TCP/IP-Familie wurden in den 70-er Jahren für den
Datenaustausch in heterogenen Rechnernetzen (d. h. Rechner verschiedener
Hersteller mit unterschiedlichen Betriebssystemen) entwickelt. TCP steht
für 'Transmission Control Protocol' (Schicht 4) und IP für 'Internet
Protocol' (Schicht 3). Die Protokollspezifikationen sind in sogenannten
RFC-Dokumenten (RFC - Request for Comment) festgeschrieben und veröffentlicht.
Aufgrund ihrer Durchsetzung stellen sie Quasi-Standards dar.
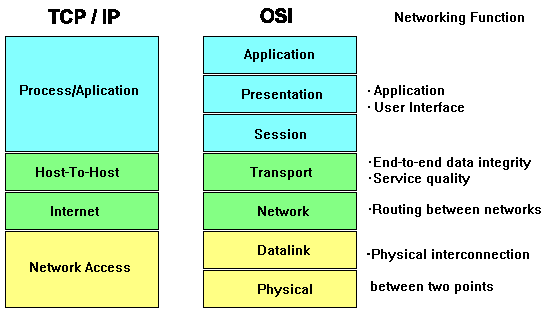
Die Schichten 5 - 7 des OSI-Standards werden hier in einer Anwendungsschicht
zusammengefaßt, da die Anwendungsprogramme alle direkt mit der
Transportschicht kommunizieren.
In Schicht 4 befindet sich außer TCP, welches gesicherten Datentransport
(verbindungsorientiert, mit Flußkontrolle (d. h.
Empfangsbestätigung, etc.) durch Windowing ermöglicht,
auch UDP (User Datagram Protocol), in welchem verbindungsloser und ungesicherter
Transport festgelegt ist. Beide Protokolle erlauben durch die Einführung
von sogenannten Ports den Zugriff mehrerer Anwendungsprogramme gleichzeitig
auf ein- und diesselbe Maschine.
In Schicht 3 ist das verbindungslose Internet-Protokoll (IP) angesiedelt.
Datenpakete werden auf den Weg geschickt, ohne daß auf eine
Empfangsbestätigung gewartet werden muß. IP-Pakete dürfen unter
bestimmten Bedingungen (TTL=0, siehe unten) sogar vernichtet werden.
In Schicht 3 werden damit auch die IP-Adressen festgelegt. Hier findet auch das Routing,
das heißt die Wegsteuerung eines Paketes von einem Netz ins andere
statt. Ebenfalls in diese Ebene integriert sind die ARP-Protokolle (ARP
- Address Resolution Protocol), die zur Auflösung (= Umwandlung) einer
logischen IP-Adresse in eine physikalische (z. B. Ethernet-) Adresse dienen
und dazu sogenannte Broadcasts (Datenpakete, durch die alle angeschloßenen
Stationen angesprochen werden) verwenden. ICMP, ein Protokoll, welches den
Austausch von Kontroll- und Fehlerpaketen im Netz ermöglicht, ist ebenfalls
in dieser Schicht realisiert.
Die Schichten 1 und 2 sind gegenüber Schicht 3 protokolltransparent.
Sie können durch standardisierte Protokolle (z. B. Ethernet (CSMA/CD),
FDDI, SLIP (Serial Line IP), PPP (Point-to-Point Protocol)) oder andere
Übertragungsverfahren realisiert werden.
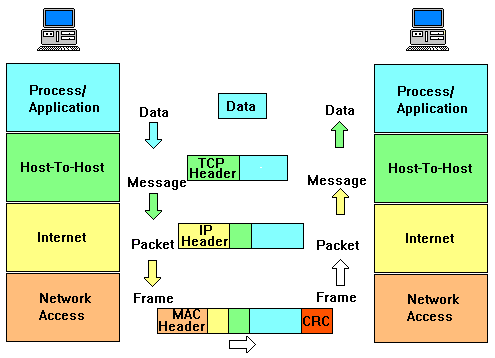
Zur TCP/IP-Familie gehören mehrere Dienstprogramme der höheren
OSI-Schichten (5 - 7), z. B.:
- Telnet (RFC 854)
Ein virtuelles Terminal-Protokoll, um vom eigenen Rechensystem einen interaktiven
Zugang zu einem anderen System zu realisieren.
- FTP (RFC 959)
Dieses (File-Transfer-) Protokoll ermöglicht, die Dateidienste eines
Fremdsystems interaktiv zu benutzen sowie die Dateien zwischen den Systemen
hin und her zu kopieren.
- NFS (RFC 1094)
Das Network File System ermöglicht den Zugriff auf Dateien an einem
entfernten System so, als wären sie auf dem eigenen. Man nennt dies
auch einen transparenten Dateizugriff. NFS basiert auf den zur TCP/IP-Familie
gehörenden UDP- (User- Datagramm-) Protokollen (ebenfalls Schicht 4),
RFC 768. Im Unterschied zu TCP baut UDP keine gesicherten virtuellen Verbindungen
zwischen kommunizierenden Hosts auf. Aufgrund dieser Eigenschaft ist es
für den Einsatz in lokalen Netzen vorgesehen.
- NNTP (RFC 977)
Das Network News Transfer Protocol spezifiziert Verteilung, Abfrage, Wiederauffinden
und das Absetzen von News-Artikeln innerhalb eines Teils oder der gesamten
Internet-Gemeinschaft. Die Artikel werden in regional zentralen Datenbasen
gehalten. Einem Benutzer ist es möglich, aus dem gesamten Angebot nur
einzelne Themen zu abonnieren.
- SMTP (RFC 821/822)
Das Simple-Mail-Transfer-Protokoll (RFC 821) ist ein auf der IP-Adressierung
sowie auf der durch den RFC 822 festgelegten Namensstruktur basierendes
Mail-Protokoll.
- DNS (RFC 920)
Der Domain Name Service unterstützt die Zuordnung von Netz- und Host-Adressen
zu Rechnernamen. Dieser Service ist z. B. erforderlich für die Anwendung
von SMTP sowie in zunehmendem Maße auch für Telnet und FTP.
Aus Sicherheitsgründen wendet sich der fremde Host an den DNS, um zu
prüfen, ob der IP-Adresse des ihn rufenden Rechners auch ein (Domain-)Name
zugeordnet werden kann. Falls nicht, wird der Verbindungsaufbau abgelehnt.
Der große Vorteil der TCP/IP-Protokollfamilie ist die einfache Realisierung
von Netzwerkverbunden. Einzelne Lokale Netze werden über Router oder
Gateways verbunden. Einzelne Hosts können daher über mehrere Teilnetze
hinweg miteinander kommunizieren.
IP als Protokoll der Ebene 3 ist die unterste Ebene, die darunter liegenden
Netzebenen können sehr unterschiedlich sein:
- LANs (Ethernet, Token-Ring, usw.)
- WANs (X.25, usw.)
- Punkt-zu-Punkt-Verbindungen (SLIP, PPP)
| Internet-Protokolle |
| OSI-Schicht |
Internet Protokoll Suite |
DOD Schicht |
| 7 |
Anwendung |
File Transfer |
Electronic
Mail |
Terminal Emulation |
Usenet News |
Domain Name Service |
World Wide Web |
Art der
Kommuni-
kation |
| 6 |
Darstellung |
File Transfer Protocol (FTP)
RFC 959 |
Simple Mail Transfer Protocol (SMTP)
RFC 821 |
Telnet Protocol (Telnet)
RFC 854 |
Usenet News Transfer Protocol (NNTP)
RFC 977 |
Domain Name Service (DNS)
RFC 1034 |
World Wide Web (WWW)
RFC |
Applikation |
| 5 |
Sitzung |
| 4 |
Transport |
Transmission Control Protocol (TCP)
RFC 793 |
User Datagram Protocol (UDP)
RFC 768 |
Host to Host Kommunikation |
| 3 |
Netzwerk |
Address Resolution Protocol (ARP)
RFC 826 |
Internet Protocol (IP)
RFC 791 |
Internet Control Messsage Protocol
RFC 792 |
Internet |
| 2 |
Sicherung |
Ethernet |
Token Ring |
DQDB |
FDDI |
ATM |
lokales Netzwerk |
| 1 |
Physikalische �bertragung |
Twisted Pair |
Lichtwellenleiter |
Coaxkabel |
Funk |
Laser |
Netzzugriff |
Es ist offensichtlich, daß die Gateways neben dem Routing weitere
nichttriviale Funktionen haben, wenn sie zwischen den unterschiedlichsten
Teilnetzen vermitteln (z. B. unterschiedliche Protokolle auf Ebene 2, unterschiedliche
Datenpaketgröße, usw.).
Aus diesem Grund existieren in einem Internet drei unabhängige Namens-
bzw. Adressierungsebenen:
- Physikalische Adressen (z. B. Ethernet-Adresse)
- Internet-Adressen (Internet-Nummer, IP-Adresse)
- Domain-Namen
Die Ethernet-Adresse wurde bereits behandelt, auf die anderen beiden Ebenen
wird in den folgenden Abschnitten eingegangen. Die Umsetzung der höchsten
Ebene (Domain-Namen) in IP-Adressen erfolgt durch das oben erwähnte
DNS, worauf die Dienstprogramm der Schichten 5-7 zurückgreifen.
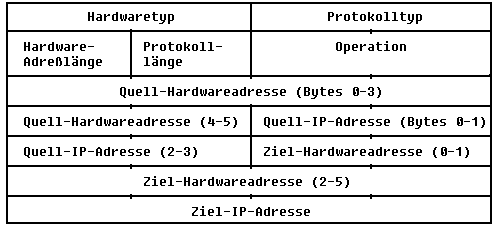
Die Umsetzung einer IP-Adresse in eine Hardware-Adresse erfolgt durch
Tabellen und auf Hardware-Ebene (z. B. Ethernet) automatisch über
ARP (Adress Resolution Protocol). Dazu ein Beispiel:
Die Station A will Daten an eine Station B mit der Internetadresse I(B)
senden, deren physikalische Adresse P(B) sie noch nicht kennt. Sie sendet
einem ARP-Request an alle Stationen im Netz, der die eigene pysikalische
Adresse und die IP-Adresse von B enthält. Alle Stationen erhalten und
überprüfen den ARP-Request und die angesprochene Station B antwortet,
indem sie einen ARP-Reply mit ihrer eigenen physikalischen Adresse an die
Station A sendet. Letztere speichert die Zuordnung in einer Tabelle (Address
Resolution Cache).
Auch für die Umkehrfunktion gibt es eine standardisierte Vorgehensweise,
den RARP (Reverse ARP). Hier sendet die Station A unter Angabe ihrer physikalischen
Adresse P(A) einen RARP-Request. Wenn im Netz nur eine Station als RARP-Server
eingerichtet ist (eine Station, die alle Zuordnungen von P(x) <-->
I(x) "kennt"), antwortet diese mit einem RARP-Reply an die anfragende
Station, der I(A) enthält. Diese Funktion ist z. B. für sogenannte
"Diskless Workstations" wichtig, die ihre gesamte Software von
einem Server laden.
Das Internet-Protokoll ist ein verbindungsloser Dienst (im Gegensatz zu
X.25) mit einem 'Unreliable Datagram Service', d. h. es wird auf der IP-Ebene
weder die Richtigkeit der der Daten noch die Einhaltung von Sequenz, Vollständigkeit
und Eindeutigkeit der Datagramme überprüft. Ein zuverlässiger
verbindungsorientierter Dienst wird in der darüberliegenden TCP-Ebene
realisiert.
Ein IP-Datagramm besteht aus einem Header und einem nachfolgenden Datenblock,
der seinerseits dann z. B. in einem Ethernet-Frame "verpackt"
wird. Die maximale Datenlänge wird auf die maximale Rahmenlänge
des physikalischen Netzes abgestimmt. Da nicht ausgeschlossen werden kann,
daß ein Datagramm auf seinem Weg ein Teilnetz passieren muß,
dessen Rahmenlänge niedriger ist, müssen zum Weitertransport mehrere
(Teil-)Datagramme erzeugt werden. Dazu wird der Header im Wesentlichen repliziert
und die Daten in kleiner Blöcke unterteilt. Jedes Teil-Datagramm hat
also wieder einen Header. Diesen Vorgang nennt man Fragmentierung. Es handelt
sich um eine rein netztechnische Maßnahme, von der Quell- und Zielknoten
nicht wissen müssen. Es gibt natürlich auch eine umgekehrte Funktion,
"Reassembly", die kleine Datagramme wieder zu einem größeren
packt. Geht auf dem Übertragungsweg nur ein Fragment verloren, muß
das gesamte Datagramm wiederholt werden. Es gilt die Empfehlung, daß
Datagramme bis zu einer Länge von 576 Bytes unfragmetiert übertragen
werden sollten.
Format des IP-Headers
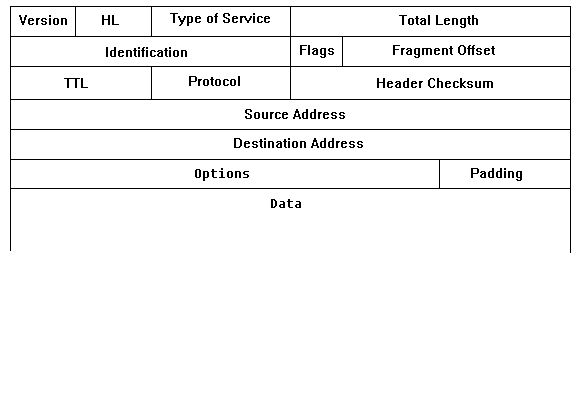
- Version
- Kennzeichnet die IP-Protokollversion
- IHL (Internet Header Length)
- Die Angabe der Länge des IP-Headers erfolgt
in 32-Bit-Worten (normalerweise 5). Da die Optionen nicht unbedingt auf
Wortlänge enden, wird der Header gegebenenfalls aufgefüllt.
- Type of Service
- Alle Bits haben nur "empfehlenden" Charakter. 'Precedence' bietet
die Möglichkeit, Steuerinformationen vorrangig zu befördern.
- Total Length
- Gesamtlänge des Datagramms in Bytes (max. 64 KByte).
- Identification
- Dieses und die beiden folgenden Felder steuern die Reassembly. Eindeutige
Kennung eines Datagramms. Anhand dieses Feldes und der 'Source Address'
ist die Zusammengehörigkeit von Fragmenten zu detektieren.
- Flags
- Die beiden niederwertigen Bits haben folgende Bedeutung:
- Don't fragment: Für Hosts, die keine Fragmentierung unterstützen
- More fragments: Zum Erkennen, ob alle Fragmente eines Datagramms empfangen wurden
- Fragment Offset
- Die Daten-Bytes eines Datagramms werden numeriert und auf die Fragmente
verteilt. Das erst Fragment hat Offset 0, für alle weiteren erhöht
sich der Wert um die Länge des Datenfeldes eines Fragments. Anhand
dieses Wertes kann der Empfänger feststellen, ob Fragmente fehlen.
Beispiel siehe unten.
- Time-to-live (TTL)
- Jedes Datagramm hat eine vorgegebene maximale Lebensdauer, die hier angegeben
wird. Auch bei Routing-Fehlern (z. B. Schleifen) wird das Datagramm irgendwann
aus dem Netz entfernt. Da Zeitmessung im Netz problematisch ist, und keine
Startzeit im Header vermerkt ist, decrementiert jeder Gateway dieses Feld
--> de-facto ein 'Hop Count'.
- Protocol
- Da sich unterschiedliche Protokolle auf IP stützen, muß das übergeordnete
Protokoll (ULP, Upper Layer Protocol) angegeben werden. Wichtige ULPs sind
- 1: ICMP Internet Control Message P.
- 3: GGP Gateway-to-Gateway P.
- 6: TCP Transmission Control P.
- 8: EGP Exterior Gateway P.
- 17: UDP User Datagram P.
- Header Checksum
- 16-Bit-Längsparität über den IP-Header (nicht die Daten)
- Source Address
- Internet-Adresse der Quellstation
- Destinantion Address
- Internet-Adresse der Zielstation
- Options
- Optionales Feld für weitere Informationen (deshalb gibt es auch die
Header-Länge). Viele Codes sind für zukünftige Erweiterungen
vorgesehen. Die Optionen dienen vor allem der Netzsteuerung, der Fehlersuche
und für Messungen. Die wichtigsten sind:
- Record Route: Weg des Datagramms mitprotokollieren
- Loose Source Routing: Die sendende Station schreibt einige Zwischenstationen
vor (aber nicht alle)
- Strict Source Routing: Die sendende Station schreibt alle Zwischenstationen
vor.
- Timestamp Option: Statt seiner IP-Adresse (wie bei Record Route) trägt
jeder Gateway den Bearbeitungszeitpunkt ein (Universal Time).
- Padding
- Füllbits
Die Hauptaufgabe von IP ist es also, die Unterschiede zwischen den verschiedenen,
darunterliegenden Netzwerkschichten zu verbergen und eine einheitliche Sicht auf die
verschiedensten Netztechniken zu präsentieren. So gibt es IP nicht nur in Netzen,
sondern auch als SLIP (Serial Line IP) oder PPP (Point to Point Protocol) für
Modem- oder ISDN-Verbindungen. Zur Vereinheitlichung gehören auch die
Einführung eines einheitlichen Adressierungsschemas und eines
Fragmentierungsmechanismus, der es ermöglicht, große
Datenpakete durch Netze mit kleiner maximaler Paketgröße
zu senden: Normalerweise existiert bei allen Netzwerken eine maximale
Größe für ein Datenpaket. Im IP-Jargon nennt man
diese Grenze die 'Maximum Transmisson Unit' (MTU). Natürlich ist
diese Obergrenze je nach verwendeter Hardware bzw. Übertragungstechnik
unterschiedlich. Die Internet-Schicht teilt IP-Pakete, die größer
als die MTU des verwendeten Netzwerks sind, in kleinere Stücke,
sogenannte Fragmente, auf. Der Zielrechner setzt diese Fragmente dann wieder zu
vollständigen IP-Paketen zusammen, bevor er sie an die darüberliegenden
Schichten weitergibt. Der Fragement Offset gibt an, an welcher Stelle in Bezug auf
den IP-Datagramm-Anfang das Paket in das Datagramm einzuordnen ist. Aufgrund des
Offset werden die Pakete in die richtige Reihenfolge gebracht. Dazu ein Beispiel:
Es soll ein TCP-Paket mit einer Länge von 250 Byte über
IP versandt werden. Es wird angenommen, daß ein IP-Header eine Länge von
20 Byte hat und eine maximale Länge von 128 Byte pro Paket nicht überschritten
werden darf Der Identifikator des Datagramms beträgt 43 und der Fragmentabstand wird
in 8-Byte-Schritten gezählt. Das Datenfragment muß also durch 8 dividierbar
sein.
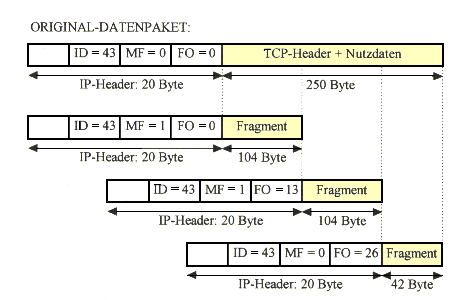
Da alle Fragmente demselben Datagramm angehören, wird der Identifikator für alle
Fragmente beibehalten. Im ersten Fragment ist das Fragment Offset natürlich noch
Null, das MF-Bit jedoch auf 1 gesetzt, um zu zeigen, daß noch Fragmente
folgen. Im IP-Header des zweiten Fragments beträgt das Fragment Offset 13
(104/8 = 13) und zeigt die Position des Fragments im Datagramm an. Das MF-Bit ist
noch immer 1, da noch ein Datenpaket folgt. Der Header des dritten Fragments
enthält dann ein MF-Bit mit dem Wert 0, denn es handelt sich um das letzte
Datenpaket zur Datagramm 43. Das Fragment Offset ist auf 26 gesetzt, da vorher schon
208 Daten-Bytes (8 * 26 = 208) übertragen wurden.
Sobald das erste Fragment (gleich welches) im Empfänger ankommt,
wird ein Timer gesetzt. Sind innerhalb der dort gesetzten Zeit nicht alle Pakete zu einem
Datagramm eingetroffen, wird angenommen, daß Fragmente verlorengingen. Der
Empfänger verwirft dann alle Datenpakete mit diesem Identifikator.
Was geschieht aber, wenn der Kommunikationspartner nicht erreichbar ist? Wie schon
erwähnt, durchläuft ein Datagramm mehrere Stationen. Diese Stationen sind in
der Regel Router oder Rechner, die gleichzeitig als Router arbeiten. Ohne
Gegenmaßnahme würde das Datenpaket für alle Zeiten durch das Netze
der Netze irren. Dazu gibt es im IP-Header neben anderer Verwaltungsinfo auch ein
Feld mit dem Namen TTL (Time To Live). Der Wert von TTL kann zwischen 0 und 255
liegen. Jeder Router, der das Datagramm transportiert, vermindert den Wert dieses
Feldes um 1. Ist der Wert von TTL bei Null angelangt, wird das Datagramm vernichtet.
Die Adressen, die im Internet verwendet werden, bestehen aus einer 32 Bit langen Zahl.
Damit sich die Zahl leichter darstellen läßt, unterteilt man sie in 4 Bytes
(zu je 8 Bit). Diese Bytes werden dezimal notiert und durch Punkte getrennt (a.b.c.d).
Zum Beispiel:
141.84.101.2
129.187.10.25
Bei dieser Adresse werden zwei Teile unterscheiden, die Netzwerkadresse und die
Rechneradresse, wobei unterschiedlich viele Bytes für beide Adressen verwendet
werden:
Die Bereiche für die Netzwerkadresse ergeben sich durch die Zuordnung der
ersten Bits der ersten Zahl (a), die eine Erkennung der Netz-Klassen
möglich machen.
| Netz-Klasse | Netzwerkadresse | Host-Adresse | Bereich binär |
| A | a b.c.d | 1 - 126 | 01xxxxxx |
| B | a.b c.d | 128 - 191 | 10xxxxxx |
| C | a.b.c d | 192 - 223 | 11xxxxxx |
Die Netzadressen von 224.x.x.x bis 254.x.x.x werden für besondere Zwecke verwendet,
z. B. 224.x.x.x für Multicast-Anwendungen.
Grundsätzlich gilt:
- Alle Rechner mit der gleichen Netzwerkadresse gehören zu einem
Netz und sind untereinander erreichbar.
- Zur Koppelung von Netzen unterschiedlicher Adresse wird eine spezielle Hardware-
oder Softwarekomponente, ein sogenannter Router, benötigt.
- Je nach Zahl der zu koppelnden Rechner wird die Netzwerkklasse gewählt.
In einem Netz der Klasse C können z. B. 254 verschiedene Rechner gekoppelt
werden (Rechneradresse 1 bis 254). Die Hostadresse 0 wird für die Identifikation
des Netzes benötigt und die Adresse 255 für Broadcast-(Rundruf-)Meldungen.
Die Netzwerkadresse 127.0.0.1 bezeichnet jeweils den lokalen Rechner (loopback address).
Sie dient der Konsistenz der Netzwerksoftware (jeder Rechner ist über
seine Adresse ansprechbar) und dem Test.
Damit man nun lokale Netze ohne Internetanbindung mit TCP/IP betreiben kann, ohne
IP-Nummern beantragen zu müssen und um auch einzelne Rechnerverbindungen
testen zu können, gibt es einen ausgesuchten Nummernkreis, der von keinen
Router nach außen gegeben wird. Diese "privaten" Adressen sind im RFC 1597
festgelegt. Es gibt ein Class-A-Netz, 16 Class-B-Netze und 255 Class-C-Netze:
- Class-A-Netz: 10.0.0.0 - 10.255.255.255
- Class-B-Netze: 172.16.0.0 - 172.31.255.255
- Class-C-Netze: 192.168.0.0 - 192.168.255.255
ICMP erlaubt den Austauch von Fehlermeldungen und Kontrollnachrichten auf
IP-Ebene. ICMP benutzt das IP wie ein ULP, ist aber integraler Bestandteil
der IP-Implementierung. Es macht IP nicht zu einem 'Reliable Service', ist
aber die einzige Möglichkeit Hosts und Gateways über den Zustand
des Netzes zu informieren (z. B. wenn ein Host temporär nicht erreichbar
ist --> Timeout).
Die ICMP-Nachricht ist im Datenteil des IP-Datagramms untergebracht, sie
enthält ggf. den IP-Header und die ersten 64 Bytes des die Nachricht
auslösenden Datagramms (z. B. bei Timeout).

Die fünf Felder der ICMP-Message haben folgende Bedeutung:
- Type
- Identifiziert die ICMP-Nachricht
- 0 Echo reply
- 3 Destination unreachable
- 4 Source quench
- 5 Redirect (Change a Route)
- 8 Echo request
- 11 Time exceeded for a datagram
- 12 Parameter Problem on a datagram
- 13 Timestamp request
- 14 Timestamp reply
- 15 Information request
- 16 Information reply
- 17 Address mask request
- 18 Address mask reply
- Code
- Detailinformation zum Nachrichten-Typ
- Checksum
- Prüfsumme der ICMP-Nachricht (Datenteil des IP-Datagramms)
- Identifier und Sequence-Nummer
- dienen der Zuordnung eintreffender Antworten
zu den jeweiligen Anfragen, da eine Station mehrere Anfragen aussenden kann
oder auf eine Anfrage mehrere Antworten eintreffen können.
Wenden wir uns nun den einzelnen Nachrichtentypen zu:
- Echo request/reply
- Überprüfen der Erreichbarkeit eines Zielknotens. Es können
Testdaten mitgeschickt werden, die dann unverändert zurückgeschickt
werden (--> Ping-Kommando unter UNIX).
- Destination unreachable
- Im Codefeld wird die Ursache näher beschrieben:
0 Network unreachable
1 Host unreachable
2 Protocol unreachable
3 Port unreachable
4 Fragmentation needed
5 Source route failed
- Source quench
- Wenn mehr Datagramme kommen als eine Station verarbeiten kann, sendet sie
diese Nachricht an die sendende Station.
- Redirect
- wird vom ersten Gateway an Hosts im gleichen Teilnetz gesendet, wenn es
eine bessere Route-Verbindung über einen anderen Gateway gibt. In der
Nachricht wird die IP-Adresse des anderen Gateways angegeben.
- Time exceeded
- Für diese Nachricht an den Quellknoten gibt es zwei Ursachen:
- Time-to-live exceeded (Code 0): Wenn ein Gateway ein Datagramm eliminiert,
dessen TTL-Zähler abgelaufen ist.
- Fragment reassembly time exceeded (Code 1): Wenn ein Timer abläuft,
bevor alle Fragmente des Datagramms eingetroffen sind.
- Parameter problem on a Datagramm
- Probleme bei der Interpretation des IP-Headers. Es wird ein Verweis
auf die Fehlerstelle und der fragliche IP-Header zurückgeschickt.
- Timestamp request/reply
- Erlaubt Zeitmessungen und -synchronisation im Netz. Drei Zeiten werden gesendet
(in ms seit Mitternacht, Universal Time):
- Originate T.: Sendezeitpunkt des Requests (vom Absender)
- Receive T.: Ankunftszeit (beim Empfänger)
- Transmit T.: Sendezeitpunkt des Reply (vom Empfänger)
- Information request/reply
- Mit dieser Nachricht kann ein Host die Netid seines Netzes erfragen, indem
er seine Netid auf Null setzt.
- Address mask request/reply
- Bei Subnetting (siehe unten) kann ein Host die Subnet-Mask erfragen.
UDP ist ein einfaches Schicht-4-Protokoll, das einen nicht zuverlässigen,
verbindungslosen Transportdienst ohne Flußkontrolle zur Verfügung
stellt. UDP ermöglicht zwischen zwei Stationen mehrere unabhängige
Kommunikationsbeziehungen (Multiplex-Verbindung): Die Identifikation der
beiden Prozesse einer Kommuninkationsbeziehung geschieht (wie auch bei TCP,
siehe unten) durch Port-Nummern (kurz "Ports"), die allgemein
bekannten Anwendungen fest zugeordnet sind. Es lassen sich aber auch Ports
dynamisch vergeben oder bei einer Anwendung durch verschiedene Ports deren
Verhalten steuern. Die Transporteinheiten werden 'UDP-Datagramme' oder 'User
Datagramme' genannt. Sie haben folgenden Aufbau:
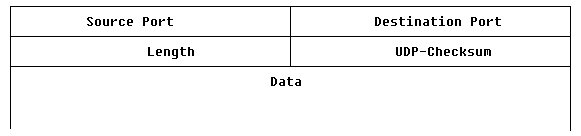
- Source Port
- Identifiziert den sendenden Prozeß (falls nicht benötigt, wird
der Wert auf Null gesetzt).
- Destination Port
- Identifiziert den Prozeß des Zielknotens.
- Length
- Länge des UDP-Datagramms in Bytes (mindestens 8 = Headerlänge)
- UDP-Checksum
- Optionale Angabe (falls nicht verwendet auf Null gesetzt) einer Prüfsumme.
Zu deren Ermittlung wird dem UDP-Datagramm ein Pseudoheader von 12 Byte
vorangestellt (aber nicht mit übertragen), der u. a. IP-Source-Address,
IP-Destination-Address und Protokoll-Nummer (UDP = 17) enthält.
Dieses Protokoll implementiert einen verbindungsorientierten, sicheren Transportdienst
als Schicht-4-Protokoll. Die Sicherheit wird durch poritive Rückmeldungen
(acknowledgements) und Wiederholung fehlerhafter Blöcke erreicht. Fast
alle Standardanwendungen vieler Betriebssysteme nutzen TCP und das darunterliegende
IP als Transportprotokoll, weshalb man die gesamte Protokollfamilie allgemein
unter 'TCP/IP' zusammenfaßt. TCP läßt sich in lokalen und
weltweiten Netzen einsetzen, da IP und die darunterliegenden Schichten mit
den unterschiedlichsten Netzwerk- und Übertragungssystemen arbeiten
können (Ethernet, Funk, serielle Leitungen, ...). Zur Realisierung
der Flußkontrolle wird ein Fenstermechanismus (sliding windows) ähnlich
HDLC verwendet (variable Fenstergröße). TCP-Verbindungen sind
vollduplex. Wie bei allen verbindungsorientierten Diensten muß zunächst
eine Virtuelle Verbindung aufgebaut und bei Beendigung der Kommunikation
wieder abgebaut werden. "Verbindungsaufbau" bedeutet hier eine
Vereinbarung beider Stationen über die Modalitäten der Übertragung
(z. B. Fenstergröße, Akzeptieren eines bestimmten Dienstes, usw.).
Ausgangs- und Endpunkte einer virtuellen Verbindung werden wie bei UDP durch
Ports identifiziert. Allgemein verfügbare Dienste (Beispiele in 4.6)
werden über 'well known' Ports (--> feste zugeordnete Portnummer)
erreichbar. Andere Portnummern werden beim Verbindungsaufbau vereinbart.
Die Fenstergröße gibt an, wieviele Bytes gesendet werden dürfen,
bis die Übertragung quittiert werden muß. Erfolgt keine Quittung,
werden die Daten nochmals gesendet. Die empfangene Quittung enthält
die Nummer des Bytes, das als nächstes vom Empfänger erwartet
wird - womit auch alle vorhergehenden Bytes quittiert sind. Die Fenstergröße
richtet sich zunächst nach der maximalen Größe eines IP-Datagramms,
sie kann aber dynamisch mit der Quittung des Empfängers geändert
werden. Werden die Ressourcen knapp, wird die Fenstergröße verringert.
Beim Extremfall Null wird die Übertragung unterbrochen, bis der Empfänger
erneut quittiert. Neben einem verläßlichen Datentransport ist
so auch die Flußkontrolle gewährleistet.
Die TCP-Übertragungseinheit zwischen Sender und Empfnänger wird
als 'Segment' bezeichnet. Jedem TCP-Block ist ein Header vorangestellt,
der aber wesentlich umfangreicher als die bisherigen ist:
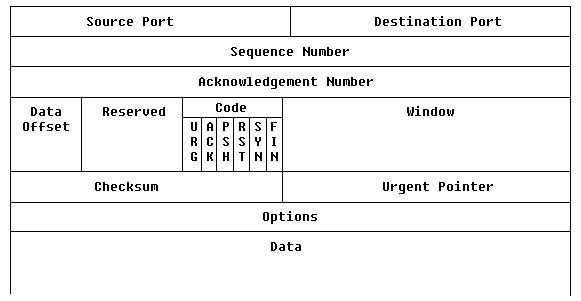
- Source Port
- Identifiziert den sendenden Prozeß.
- Destination Port
- Identifiziert den Prozeß des Zielknotens.
- Sequence Number
- TCP betrachtet die zu übertragenden Daten als numerierten Bytestrom,
wobei die Nummer des ersten Bytes beim Verbindungsaufbau festgelegt wird.
Dieser Bytestrom wird bei der Übertragung in Blöcke (TCP-Segmente)
aufgeteilt. Die 'Sequence Number' ist die Nummer des ersten Datenbytes im
jeweiligen Segment (--> richtige Reihenfolge über verschiedene Verbindungen
eintreffender Segmente wiederherstellbar).
- Acknowledgement Number
- Hiermit werden Daten von der Empfängerstation bestätigt, wobei
gleichzeitig Daten in Gegenrichtung gesendet werden. Die Bestätigung
wird also den Daten "aufgesattelt" (Piggyback). Die Nummer bezieht
sich auf eine Sequence-Nummer der empfangenen Daten; alle Daten bis zu dieser
Nummer (ausschließlich) sind damit bestätigt --> Nummer des
nächsten erwarteten Bytes. Die Gültigkeit der Nummer wird durch
das ACK-Feld (--> Code) bestätigt.
- Data Offset
- Da der Segment-Header ähnlich dem IP-Header Optionen enthalten kann,
wird hier die Länge des Headers in 32-Bit-Worten angegeben.
- Res.
- Reserviert für spätere Nutzung
- Code
- Angabe der Funktion des Segments:
- URG Urgent-Pointer (siehe unten)
- ACK Quittungs-Segment (Acknowledgement-Nummer gültig)
- PSH Auf Senderseite sofortiges Senden der Daten (bevor Sendepuffer
gefüllt ist) und auf Empfangsseite sofortige Weitergabe an die Applikation
(bevor Empfangspuffer gefüllt ist) z. B. für interaktive Programme.
- RST Reset, Verbindung abbauen
- SYN Das 'Sequence Number'-Feld enthält die initiale Byte-Nummer
(ISN) --> Numerierung beginnt mit ISN + 1. In der Bestätigung
übergibt die Zielstation ihre ISN (Verbindungsaufbau).
- FIN Verbindung abbauen (Sender hat alle Daten gesendet), sobald der
Empfänger alles korrekt empfangen hat und selbst keine Daten mehr loswerden
will.
- Window
- Spezifiziert die Fenstergröße, die der Empfänger bereit
ist anzunehmen - kann dynamisch geändert werden.
- Checksum
- 16-Bit Längsparität über Header und Daten.
- Urgent Pointer
- Markierung eines Teils des Datenteils als dringend. Dieser wird unabhängig
von der Reihenfolge im Datenstrom sofort an das Anwenderprogramm weitergegeben
(URG-Code muß gesetzt sein). Der Wert des Urgent-Pointers markiert
das letzte abzuliefernde Byte; es hat die Nummer <Sequence Number>
+ <Urgent Pointer>.
- Options
- Dieses Feld dient dem Informationsaustausch zwischen beiden Stationen auf
der TCP-Ebene, z. B. die Segmentgröße (die Ihrerseits von der
Größe des IP-Datagramms abhängen sollte, um den Durchsatz
im Netz optimal zu gestalten).
Ablauf einer TCP-Session
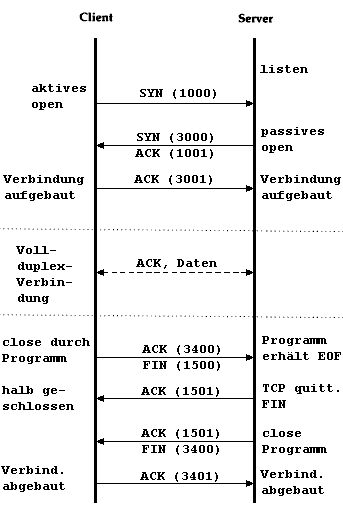
Beim Öffnen einer TCP-Verbindung tauschen beide Kommunikationspartner
Kontrollinformationen aus, die sicherstellen, daß der jeweilige Partner
existiert und Daten annehmen kann. Dazu schickt die Station A ein Segment mit der
Aufforderung, die Folgenummern zu synchronisieren.
Das einleitende Paket mit gesetztem SYN-Bit ("Synchronise-" oder "Open"-Request)
gibt die Anfangs-"Sequence Number" des Client bekannt. Diese Anfangs-"Sequence
Number wird zufällig bestimmt. Bei allen nachfolgenden Paketen ist das
ACK-Bit ("Acknowledge", "Quittung") gesetzt. Der Server antwortet mit ACK, SYN
und der Client bestätigt mit ACK. Das sieht dann so aus:
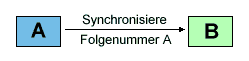
Die Station B weiß jetzt, daß
der Sender eine Verbindung öffnen möchte und an welcher
Position im Datenstrom der Sender anfangen wird zu zählen. Sie
bestätigt den Empfang der Nachricht und legt ihrerseits eine
Folgenummer für Übertragungen in Gegenrichtung fest.

Station A bestätigt nun den Empfang der Folgenummer von B und beginnt
dann mit der Übertragung von Daten.

Diese Art des Austausches von Kontrollinformationen, bei der jede Seite die Aktionen
der Gegenseite bestätigen muß, ehe sie wirksam werden können,
heißt "Dreiwege-Handshake". Auch beim Abbau einer Verbindung wird auf diese
Weise sichergestellt, daß beide Seiten alle Daten korrekt und vollständig
empfangen haben.
Das folgende Beispiel zeigt die Arbeitsweise des TCP/IP - Protokolls. Es wird
eine Nachricht vn einem Rechner im grünen Netz zu einem Rechner im orangen
Netz gesendet.
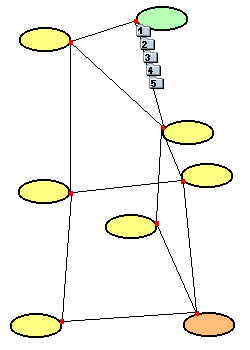
- Die Nachricht wird in mehrere Pakete aufgeteilt und auf der besten Route
auf die Reise geschickt. Das verbindungslose IP-Protokoll sorgt zusammen mit
den Routern für den Weg.
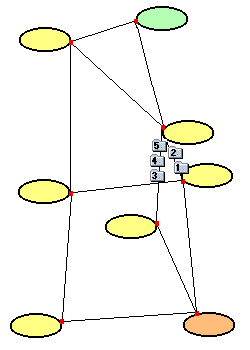
- Da eine Strecke überlastet ist, werden die Pakete 3, 4 und 5 auf einer
anderen Strecke weiter transportiert. Dieser Transport erfolgt zufälligerweise
schneller als jener der Pakete 1 und 2.
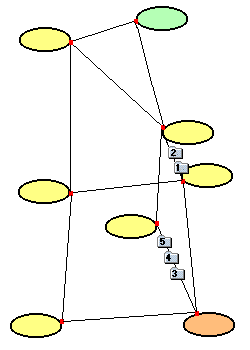
- Die Pakete wandern ihrem Bestimmungsnetz entgegen. Das erste Paket ist
bereits angekommen. Paket 3 kommt vor Paket 2 am Ziel an.
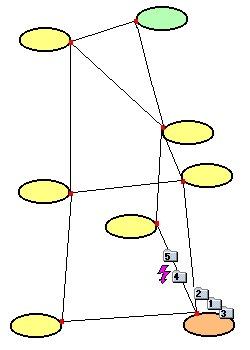
- Die Pakete 1, 2 und 3 sind - in falscher Reihenfolge - am Zielrechner angekommen.
Auf der Strecke, auf der Pakete 4 und 5 transportiert werden, tritt eine Störung
auf.
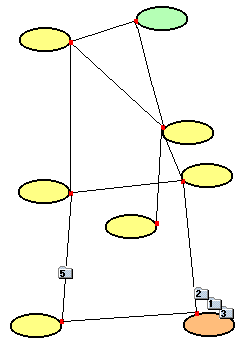
- Paket 4 ist bei der Störung verloren gegangen. Paket 5 wird auf einer
anderen Route zum Zielnetz geschickt (wären die Routen statisch am Router
eingetragen, ginge auch Paket 5 verloren).
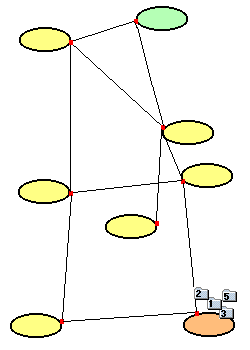
- Alle überlebenden Pakete sind am Zielrechner angekommen. Das TCP-Protokoll
setzt die Pakete wieder in der richtigen Reihenfolge zusammen und fordert das
fehlende Paket 4 nochmals beim Sender an. Für den Empfänger ergibt sich
ein kontinuierlicher Datenstrom.
Server-Prozesse lauschen auf bestimmten Portnummern ("listen"). Per Übereinkunft
werden dazu Ports niedriger Nummern verwendet. Für die Standarddienste sind
diese Portnummern in den RFCs festgeschrieben. Ein Port im listen-Modus ist
gewissermaßen eien Halboffene Verbindung. Nur Quell-IP und Quellport sind
bekannt. Der Serverprozeß kann vom Betriebssystem dupliziert werden,
so daß weitere Anfragen auf diesem Port behandelt werden können.
Die Client-Prozesse verwenden normalerweise freie Portnummern, die vom
lokalen Betriebssystem zugewiesen werden (Portnummer > 1024).
TCP-Zustandsübergangsdiagramm
Den gesamte Lebenszyklus einer TCP-Verbindung beschreibt die folgende Grafik in einer
relativ groben Darstellung.
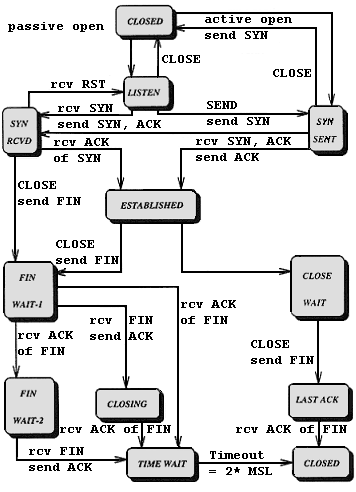
Erklärung der Zustände:
- LISTEN: Warten auf ein Connection Request.
- SYN-SENT: Warten auf ein passendes Connection Request,
nachdem ein SYN gesendet wurde.
- SYN-RECEIVED: Warten auf Bestätigung des Connection Request
Acknowledgement, nachdem beide Teilnehmer ein Connection Request
empfangen und gesendet haben.
- ESTABLISHED: Offene Verbindung.
- FIN-WAIT-1: Warten auf ein Connection Termination Request des Kommunikationspartners
oder auf eine Bestätigung des Connection Termination, das vorher gesendet wurde.
- FIN-WAIT-2: Warten auf ein Connection Termination Request des Kommunikationspartners.
- CLOSE-WAIT: Warten auf ein Connection Termination Request (CLOSE) der darüberliegenden
Schicht.
- CLOSING: Warten auf ein Connection Termination Request des Kommunikationspartners.
LAST-ACK: Warten auf die Bestätigung des Connection Termination Request, das zuvor an
den Kommunikationspartner gesendet wurde.
Die Hauptmerkmale von TCP
- verbindungsorientierter Dienst
- vollduplexfähig
- hohe Zuverlässigkeit
- Sicherung der Datenübertragung durch Prüfsumme und Quittierung mit Zeitüberwachung
- Sliding Window Verfahren
- Möglichkeit von Vorrangdaten
- Adressierung der Ende-zu-Ende-Verbindung durch Portnummern in Verbindung mit IP-Adressen
Normalerweise stützen sich Programme auf Anwendungseben auf mehrere
der Protokolle (ICMP, UDP, TCP).
Das rasche (exponentielle Wachstum) des Internet zwingt dazu, das Internet Protokoll
in der Version 4 (IPv4) durch ein Nachfolgeprotokoll (IPv6 Internet Protocol
Version 6) zu ersetzen.
Vinton Cerf (der 'Vater' des Internet) bezeichnet in einem Interview mit der Zeitschrift
c't das Internet "(...) als die wichtigste Infrastruktur für alle Arten
von Kommunikation.". Auf die Frage, wie man sich die neuen Kommunikationsdienste
des Internet vorstellen könne, antwortete Cerf:
"Am spannendsten finde ich es, die ganzen Haushaltsgeräte ans Netz anzuschließen. Ich denke
dabei nicht nur daran, daß der Kühlschrank sich in Zukunft mit der Heizung austauscht, ob es in der
Küche zu warm ist. Stromgesellschaften könnten beispielsweise Geräte wie Geschirrspülmaschinen
kontrollieren und ihnen Strom genau dann zur Verfügung stellen, wenn gerade keine Spitzennachfrage herrscht.
Derartige Anwendungen hängen allerdings davon ab, daß sie zu einem erschwinglichen Preis angeboten werden.
Das ist nicht unbedingt ferne Zukunftsmusik; die Programmierer müßten eigentlich nur damit anfangen,
endlich Software für intelligente Netzwerkanwendungen zu schreiben. Und natürlich muß die Sicherheit
derartiger Systeme garantiert sein. Schließlich möchte ich nicht, daß die Nachbarkinder mein Haus
programmieren!"
Auf die Internet Protokolle kommen in der nächsten Zeit also völlig neue
Anforderungen zu.
Classless InterDomain Routing - CIDR
Der Verknappung der Internet-Adressen durch die ständig steigende Benutzerzahl
wird zunächst versucht, mit dem Classless Inter-Domain Routing (CIDR)
entgegen zu wirken.
Durch die Vergabe von Internet-Adressen in Klassen (A,B,C,...) wird eine große Anzahl
von Adressen verschwendet. Hierbei stellt sich vor allem die Klasse B als Problem dar.
Viele Firmen nehmen ein Netz der Klasse B für sich in Anspruch, da ein Klasse A Netz
mit bis zu 16 Mio. Hosts selbst für eine sehr große Firma überdimensioniert
scheint, ein Netz der Klasse C mit 254 Hosts aber zu klein.
Ein größerer Host-Bereich für Netze der Klasse C (z. B. 10 Bit, 1022 Hosts
pro Netz) hätte das Problem der knapper werdenden IP-Adressen vermutlich gemildert.
Ein anderes Problem wäre dadurch allerdings entstanden: die Einträge der
Routing-Tabellen hätten sich um ein Vielfaches vermehrt.
Ein anderes Konzept ist das Classless Inter-Domain Routing (RFC 1519): die verbleibenden
Netze der Klasse C werden in Blöcken variabler Größe zugewiesen. Werden
beispielsweise 2000 Adressen benötigt, so können einfach acht aufeinanderfolgende
Netze der Klasse C vergeben werden. Zusätzlich werden die verbliebenen Klasse-C-Adressen
restriktiver und strukturierter vergeben (RFC 1519). Die Welt ist dabei in vier Zonen
aufgeteilt, von denen jede einen Teil des verbliebenen Klasse C Adreßraums erhält:
| 194.0.0.0 - 195.255.255.255 | Europa |
| 198.0.0.0 - 199.255.255.255 | Nordamerika |
| 200.0.0.0 - 201.255.255.255 | Mittel- und Südamerika |
| 202.0.0.0 - 203.255.255.255 | Asien und pazifischer Raum |
| 204.0.0.0 - 223.255.255.255 | Reserviert für zukünftige Nutzung |
Jede der Zonen erhält dadurch in etwa 32 Millionen Adressen zugewiesen. Vorteil bei
diesem Vorgehen ist, daß die Adressen einer Region im Prinzip zu einem Eintrag in
den Routing-Tabellen komprimiert worden sind und jeder Router, der eine Adresse
außerhalb seiner Region zugesandt bekommt diese getrost ignorieren darf.
Internet Protokoll Version 6 - IPv6 (IP Next Generation, IPnG)
Der vorrangige Grund für eine Änderung des IP-Protokolls ist auf den
begrenzten Adreßraum und das Anwachsen der ROuting-Tabellen zurückzuführen.
CIDR schafft hier zwar wieder etwas Luft, dennoch ist klar absehbar, daß auch
diese Maßnahme nicht ausreicht, um die Verknappung der Adressen für eine
längere Zeit in den Griff zu bekommen. Weitere Gründe für eine
Änderung des IP-Protokolls sind die neuen Anforderungen an das Internet, denen IPv4
nicht gewachsen ist. Streaming-Verfahren wie Real-Audio oder Video-on-Demand erfordern
das Festlegen eines Mindestdurchsatzes, der nicht unterschritten werden darf. Bei IPv4
kann so ein "Quality of Service" jedoch nicht definiert - und damit auch nicht
sichergestellt - werden. Die IETF (Internet Engineering Task Force) begann
deshalb 1990 mit der Arbeit an einer neuen Version von IP. Die wesentlichen Ziele des
Projekts sind:
- Unterstützung von Milliarden von Hosts, auch bei ineffizienter Nutzung des Adreßraums
- Reduzierung des Umfangs der Routing-Tabellen
- Vereinfachung des Protokolls, damit die Router Pakete schneller abwickeln können
- Höhere Sicherheit (Authentifikation und Datenschutz) als das heutige IP
- Mehr Gewicht auf Dienstarten, insbesondere für Echtzeitanwendungen
- Unterstützung von Multicasting durch die Möglichkeit, den Umfang zu definieren
- Möglichkeit für Hosts, ohne Adreßänderung auf Reise zu gehen (Laptop)
- Möglichkeit für das Protokoll, sich zukünftig weiterzuentwickeln
- Unterstützung der alten und neuen Protokolle in Koexistenz für Jahre
Im Dezember 1993 forderte die IETF mit RFC 1550 die Internet-Gemeinde dazu auf,
Vorschläge für ein neues Internet Protokoll zu machen. Auf die Anfrage
wurde eine Vielzahl von Vorschlägen eingereicht. Diese reichten von nur
geringfügigen Änderungen am bestehenden IPv4 bis zur vollständigen
Ablösung durch ein neues Protokoll. Aus diesen Vorschlägen wurde von der
IETF das Simple Internet Protocol Plus (SIPP) als Grundlage für die neue
IP-Version ausgewählt.
Als die Entwickler mit den Arbeiten an der neuen Version des Internet Protokolls begannen,
wurde ein Name für das Projekt bzw. das neue Protokoll benötigt. Angeregt durch
die Fernsehserie "Star Trek - Next Generation", wurde als Arbeitsname IP - Next
Generation (IPnG) gewählt. Schließlich bekam das neue IP eine offizielle
Versionsnummer zugewiesen: IP Version 6 oder kurz IPv6. Die Protokollnummer 5 (IPv5)
wurde bereits für ein experimentelles Protokoll verwendet.
Die Merkmale von IPv6
Viele der Merkmale von IPv4 bleiben in IPv6 erhalten. Trotzdem ist IPv6 im allgemeinen
nicht mit IPv4 kompatibel, wohl aber zu den darüberliegenden Internet-Protokollen,
insbesondere den Protokollen der Transportschicht (TCP, UDP). Die wesentlichen Merkmale
von IPv6 sind:
- Adreßgröße: Statt bisher 32 Bit stehen nun 128 Bit
für die Adressen bereit. Theoretisch lassen sich damit 2128
= 3.4*1038 Adressen vergeben.
- Header-Format: Der IPv6-Header wurde vollständig geändert. Der
Header enthält nur sieben statt bisher 13 Felder. Diese Änderung ermöglicht
die schneller Verarbeitung der Pakete im Router. Im Gegensatz zu IPv4 gibt es bei IPv6
nicht mehr nur einen Header, sondern mehrere Header. Ein Datengramm besteht
aus einem Basis-Header, sowie einem oder mehreren Zusatz-Headern, gefolgt von den Nutzdaten.

- Erweiterte Unterstützung von Optionen und Erweiterungen: Die Erweiterung
der Optionen ist notwendig geworden, da einige der bei IPv4 notwendige Felder nun optional
sind. Darüber hinaus unterscheidet sich auch die Art, wie die Optionen dargestellt
werden. Für Router wird es damit einfacher, Optionen, die nicht für
sie bestimmt sind, zu überspringen.
- Dienstarten: IPv6 legt mehr Gewicht auf die Unterstützung von
Dienstarten. Damit kommt IPv6 den Forderungen nach einer verbesserten Unterstützung
der Übertragung von Video- und Audiodaten entgegen, z. B. durch eine Option zur
Echtzeitübertragung.
- Sicherheit: IPv6 beinhaltet nun im Protokoll selbst Mechanismen zur sicheren
Datenübertragung. Wichtige neue Merkmale von IPv6 sind hier Authentifikation,
Datenintegrität und Datenverlässlichkeit.
- Erweiterbarkeit: IPv6 ist ein erweiterbares Protokoll. Bei der Spezifikation
des Protokolls wurde nicht versucht, alle möglichen Einsatzfelder für das
Protokoll in die Spezifikation zu integrieren. Über Erweiterungs-Header kann das
Protokoll erweitert werden.
Aufbau des IPv6-Basis-Headers
Im IPv6 wird im Vergleich zum IPv4 auf eine Checksumme verzichtet,
um den Routern die aufwendige Überprüfung - und damit Rechenzeit
- zu ersparen. Ein Übertragungsfehler muss deshalb in den höheren
Schichten erkannt werden. Der Paketkopf ist durch die Verschlankung
nur doppelt so groß, wie ein IPv4-Header.
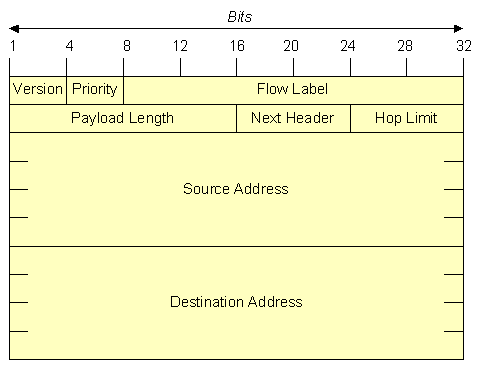
- Version:
-
Mit dem Feld Version können Router überprüfen, um welche
Version des Protokolls es sich handelt. Für ein IPv6-Datengramm ist dieses Feld
immer 6 und für ein IPv4-Datengramm dementsprechend immer 4. Mit diesem Feld
ist es möglich für eine lange Zeit die unterschiedlichen Protokollversionen
IPv4 und IPv6 nebeneinander zu verwenden. Über die Prüfung des Feldes
Version können die Daten an das jeweils richtige "Verarbeitungsprogramm"
weitergeleitet werden.
- Priority:
-
Durch das Feld Priority (oder Traffic Class) kann angegeben
werden, ob ein Paket bevorzugt behandelt werden muß. Dies ist für die
Anpassung des Protokolls an die neuen Real Time Anwendungen nötig geworden.
Damit können zum Beispiel Videodaten den Emaildaten vorgezogen werden.Bei
einem Router unter Last besteht damit die Möglichkeit der Flusskontrolle.
Pakete mit kleinerer Priorität werden verworfen und müssen wiederholt
werden.Mit den vier Bit lassen sich 16 Prioritäten angeben, wovon
1 bis 7 für "Non Real Time"- und 8 bis 15 für "Real Time"-Anwendungen
reserviert sind. Die Zahl Null gibt an, dass die Priorität des
Verkehrs nicht charakterisiert ist.
- Flow Label
-
Mit Hilfe des Feldes Flow Label können Eigenschaften des Datenflusses
zwischen Sender und Empfänger definiert werden. Das Flow
Label selbst ist nur eine Zufallszahl. Die Eigenschaften müssen
durch spezielle Protokolle oder durch den Hop-by-Hop-Header in den Routern
eingestellt werden. Eine Anwendung ist zum Beispiel, daß die Pakete eines
Flusses immer den gleichen Weg im Netz nehmen. Durch Speichern der Informationen
für das jeweilige Flow-Label, muß der Router bestimmte Berechnungen nur
für das erste Paket ausführen, und kann danach für alle Folgepakete
die Resultate verwenden. Erst die Einführung des Flow Labels ermöglicht
die Einführung von Quality-of-Service-Parametern im IP-Verkehr.
- Payload Length
-
Das Feld Payload Length (Nutzdatenlänge) gibt an, wie viele Bytes
dem IPv6-Basis-Header folgen, der IPv6-Basis-Header ist ausgeschlossen. Die
Erweiterungs-Header werden bei der Berechnung der Nutzdatenlänge mit einbezogen.
Das entsprechende Feld wird in der Protokollversion 4 mit Total Length bezeichnet.
Allerdings bezieht IPv4 den 20 Byte großen Header auch in die Berechnung ein,
wodurch die Bezeichnung "total length" gerechtfertigt ist.
- Next Header
-
Das Feld Next Header gibt an, welcher Erweiterungs-Header dem IPv6-Basis-Header
folgt. Jeder folgende Erweiterungs-Header beinhaltet ebenfalls ein Feld Next Header, das
auf den nachfolgenden Header verweist. Beim letzten IPv6-Header, gibt das Feld an, welches
Transportprotokoll (z.B. TCP oder UDP) folgt.
- Hop Limit
-
Im Feld Hop Limit wird festgelegt, wie lange ein Paket überleben darf.
Der Wert des Feldes wird von jedem Router vermindert. Ein Datengramm wird verworfen,
wenn das Feld den Wert Null hat. IPv4 verwendete hierzu das Feld Time to Live.
Die Bezeichnung bringt mehr Klarheit, da schon in IPv4 die Anzahl Hops gezählt
und nicht die Zeit gemessen wurde.
- Source Address, Destination Address
-
Die beiden Felder für Quell- und Zieladresse dienen zur
Identifizierung des Senders und Empfängers eines IP-Datengramms. Bei IPv6 sind
die Adressen vier mal so groß wie IPv4: 128 Bit statt 32 Bit.
Das Feld Length (Internet Header Length - IHL) von IPv4 ist nicht
mehr vorhanden, da der IPv6-Basis-Header eine feste Länge von 40 Byte hat.
Das Feld Protocol wird durch das Feld Next Header ersetzt.
Alle Felder die bisher zur Fragmentierung eines IP-Datengramms benötigt wurden
(Identification, Flags, Fragment Offset), sind im IPv6-Basis-Header nicht
mehr vorhanden, da die Fragmentierung in IPv6 gegenüber IPv4 anders gehandhabt
wird. Alle IPv6-kompatiblen Hosts und Router müssen Pakete mit einer Größe
von 1280 Byte unterstützen. Empfängt ein Router ein zu großes Paket, so
führt er keine Fragmentierung mehr durch, sondern sendet eine Nachricht an den
Absender des Pakets zurück, in der er den sendenden Host anweist, alle weiteren
Pakete zu diesem Ziel aufzuteilen. Es wird also vom Hosts erwartet, daß er
von vornherein eine passende Paketgröße wählt. Die Steuerung der
Fragmentierung erfolgt bei IPv6 über den Fragment Header.
Das Feld Checksum ist nicht mehr vorhanden.
Erweiterungs-Header im IPv6
Bei IPv6 muß nicht mehr der ganze optionale Teil des Headers von allen Routern
verarbeitet werden, womit wiederum Rechenzeit eingespart werden kann. Diese
optionalen Header werden miteinander verkettet. Jeder optionale Header beinhaltet
die Identifikation des folgenden Header. Es besteht auch die Möglichkeit
selber Optionen zu definieren.
Derzeit sind sechs Erweiterungs-Header definiert. Alle Erweiterungs-Header sind optional.
Werden mehrere Erweiterungs-Header verwendet, so ist es erforderlich, sie in einer
festen Reihenfolge anzugeben.
| Header
| Beschreibung
|
| IPv6-Basis-Header |
Zwingend erforderlicher IPv6-Basis-Header |
Optionen für Teilstrecken
(Hop-by-Hop Options Header) |
Dies ist der einzige optionale Header, der von jedem Router bearbeitet
werden muß. Bis jetzt ist nur die "Jumbo Payload Option" definiert, in der die
Länge eines Paketes angegeben werden kann, das länger als 64 KByte ist.
|
Optionen für Ziele
(Destination Options Header) |
Zusätzliche Informationen für das Ziel |
Routing
(Routing Header) |
Definition einer vollständigen oder teilweisen Route.
Er wird für das Source-Routing in IPv6 verwendet. |
Fragmentierung
(Fragment Header) |
In IPv6 wird, wie oben beschrieben, die Fragmentierung nur
noch End to End gemacht. Die Fragmentierinformationen werden in diesem
optionalen Header abgelegt.
|
Authentifikation
(Authentication Header) |
Er dient der digitalen Signatur von Paketen, um die Quelle eindeutig
feststellen zu können.
|
Verschlüsselte Sicherheitsdaten
(Encapsulating Security Payload Header) |
Informationen über den verschlüsselten Inhalt. |
Optionen für Ziele
(Destination Options Header) |
Zusätzliche Informationen für das Ziel (für
Optionen, die nur vom endgültigen Ziel des Paketes verarbeitet werden
müssen). |
Header der höheren Schichten
(Upper Layer Header) |
Header der höheren Protokollschichten (TCP, UDP, ...) |
IPv6-Adressen
Die IPv6-Adressen sind zwar von 32 Bit auf 128 Bit angewachsen, trotzdem sind die
grundsätzlichen Konzepte gleich geblieben. Die Adresse wird normalerweise
Sedezimal (Hexadezimal, Basis 16) notiert und hat die allgemeine Form
xxxx:xxxx:xxxx:xxxx:xxxx:xxxx:xxxx:xxxx
Sie ist damit recht länglich. Um die Schreibweise zu vereinfachen,
wurden einige Regeln eingeführt:
In IPv4 wurden die Adressen anfänglich in die bekannten Klassen eingeteilt.
Ein weiteres Problem bei den IPv4 Adressen ist, daß die Router keine
Hierarchie in den Adressen erkennen können. Auch IPv6 ist in der allgemeinen
Form unstrukturiert, es kann aber durch definierte Präfixe strukturiert werden.
Die allgemein strukturiert Adresse sieht danach wie folgt aus:

Die Strukturierung erlaubt die Einteilung der Adresse in Adresstypen. Jeder Präfix
identifiziert somit einen Adresstyp. Die bereits definierten Adresstypen und die
zugehörigen Präfixe sind:
| Adresstyp | Präfix (binär) |
|---|
| Reserviert für IPv4 und Loopback | 0000 0000 |
| NSAP-Adressen | 0000 001 |
| IPX-Adressen | 0000 010 |
| Anbieterbasierte Unicast-Adresse | 010 |
| Reserviert für geografische Unicast-Adresse | 100 |
| Zusammenfassbare globale Adressen | 001 |
| Standortlokale Adresse | 1111 1110 11 |
| Multicast-Adresse | 1111 1111 |
Wie man in der Tabelle erkennen kann, werden die Adressen grob in die Typen
Unicast, Multicast und Anycast eingeteilt, deren Eigenschaften
nachfolgend kurz erklärt werden sollen.
- Unicast
Als Unicast-Adressen bezeichnet man die Adressen, die für Punkt-zu-Punkt-Verbindungen
verwendet werden. Sie werden in verschiedene Gruppen eingeteilt:
- Linklokale und standortlokale Adressen
Diese Adressen werden für die TCP/IP-Dienste innerhalb eines Unternehmens
genutzt. Die Linklokalen Adressen werden nicht in das Internet geroutet und haben
den folgenden Aufbau:

Im Gegensatz dazu stehen die standortlokalen Adressen, die nur innerhalb eines
Subnetzes gültig sind und deshalb von keinem Router behandelt werden.

- Multicast-Adressen
In IPv4 wird das Rundsenden eines Paketes an mehrere Stationen durch das IGMP
(Internet Group Management Protokoll) realisiert. In IPv6 ist das Prinzip
übernommen, aber ein eigener Adresstyp definiert worden. IGMP entfällt
somit gänzlich. Das Paket für Multicast-Meldungen sieht wie folgt aus:
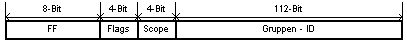
Das Flag gibt an, ob die Gruppen ID temporär, oder von der IANA
zugewiesen ist. Der Scope gibt den Gültigkeitsbereich der Multicast
Adresse an. Dieser reicht vom nodelokalen bis zum globalen Bereich.
- Anycast Adressen
Diese Adressen sind neu definiert worden. es können mehrere Rechner zu einer
Gruppe zusammengefasst werden und sie sind dann unter einer einzigen Adresse erreichbar.
Damit ist beispielsweise eine Lastverteilung möglich: der Rechner, der am wenigsten
belastet ist, behandelt das Paket. Die Adresse hat die folgende Struktur:
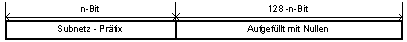
Sicherheit
Der Bedarf an digitalen Unterschriften oder elektronischen Zahlungsmöglichkeiten
steigt ständig. Deshalb stand bei der Spezifikation von IPv6 die Sicherheit von
Anfang an im Mittelpunkt. Für die Sicherheitsfunktionen von IPv6 ist eine
spezielle Arbeitsgruppe "IPSec" zuständig.
In IPv6 wurden Sicherheitsmechanismen für die Authentisierung und Verschlüsselung
auf IP Ebene spezifiziert. Die Verschlüsselungsfunktionen definieren Verfahren
um das Mitlesen durch Unbefugte zu verhindern. Es gibt zwei unterschiedliche Ansätze.
Bei der ersten Variante werden alle Nutzdaten (Payload) verschlüsselt. Der Header
bleibt normal lesbar. Bei der anderen Variante ist es möglich, den Header
ebenfalls zu verschlüsseln. Das codierte Paket wird in ein anderes IPv6-Packet
verpackt und zu einem fixen Ziel befördert ("IP-Tunnel"). Am Ziel wird das Paket
wieder entschlüsselt und über das sichere interne Netz übertragen.
Authentisierungsmechanismen liefern den Beweis auf Unverfälschtheit
der Nachricht und identifiziert den Absender (Digitale Unterschrift).
Hier werden verschiedene kryptographische Verfahren eingesetzt.
Die Verfahren für die Verschlüsselung und die Authentisierung
können auch getrennt angewandt werden.
Verwaltung und Verteilung der Schlüssel wird nicht von IPv6 gelöst.
Das Standardverfahren für den IPv6-Authentisierungsmechanismus
ist MD5 mit 128 Bit langen Schlüsseln. IPv6 schreibt keinen
Verschlüsselungsmechanismus vor, jedes System im Internet
muß jedoch den DES mit CBD (Cipher Block Chaining) unterstützen.
 Zum Inhaltsverzeichnis
Zum Inhaltsverzeichnis
 Zum nächsten Abschnitt
Zum nächsten Abschnitt
Copyright © Prof. Jürgen Plate, Fachhochschule München