 |
Vorlesung "UNIX"von Prof. Jürgen Plate |
|
Vorlesung "UNIX"von Prof. Jürgen Plate |
| -s | Unterdrückt die Anzeige der gelesenen/geschriebenen Bytes. |
| -p | Nach dem p wird ein Promptzeichen angegeben, das der ed dann im Kommandomodus ausgibt (z. B. -p#). |
Der ed kennt zwei Verarbeitungsmodi, den Kommandomodus und den Eingabemodus. Nach dem Aufruf befindet er sich immer im Kommandomodus und, falls schon eine Text vorhanden war, am Ende der Datei. Um in den Eingabemodus zu gelangen, muß eines der folgenden Kommandos gegeben werden:
| a | (append) Anhängen des Textes an die aktuelle Zeile |
| i | (insert) Einfügen des Textes vor der akt. Zeile |
| c | (change) Ersetzen von Text durch die Eingabe |
Die maximale Zeilenlänge beträgt 512 Zeichen. Zur Korrektur gibt es nur "Backspace" (#, CTRL-H) und "Zeile löschen" (@, CTRL-X). Zurück in den Kommandomodus gelangt man durch eine Zeile, die als einziges Zeichen einen Punkt enthält. ed arbeitet zeilenorientiert, wobei ein interner Zeiger immer auf eine bestimmte Zeile zeigt (zu Beginn auf die letzte Zeile). Ein ed-Kommando besteht aus Zeilenadresse und Editier-Anweisung, wobei bei fehlender Adresse die aktuelle Zeile verwendet wird:
[Anfangsadresse [,Endadresse]] Anweisung
Man kann also eine einzige Zeile oder einen Bereich definieren:
| Bereich | Beispiel | Bedeutung |
|---|---|---|
| Zeilennr. | 5 | setze Zeiger auf die angegebene Zeile |
| Z-Nr , Z-Nr | 1,5 | bearbeite Zeilen 1 bis 5 |
| $ | $ | letzte Zeile |
| . | . | aktuelle Zeile |
| .,$ | .,$ | von der aktuellen Zeile bis Dateiende |
| 1,. | 1,. | von der ersten Zeile bis zur aktuellen Zeile |
| 1,$ | 1,$ | gesamter Text |
| Z-Nr,$ | 20,$ | bearbeite Zeile 20 bis Ende |
| keine Angabe | Return-Taste | nächste Zeile |
Außerdem ist relative Adressierung mit +n oder -n (n = Zahl)
möglich, z. B. adressiert .,.+10 die folgenden 10 Zeilen.
Eine weitere Möglichkeit der Adressierung ist ein regulärer Ausdruck
(dazu unten noch mehr):
/reg.Ausdr./ Sucht ab der aktuellen Zeile (bis $) nach einer Zeile, die den
regulären Ausdruck erfüllt. Wird keine solche Zeile gefunden, wird ab Zeile
1 bis zur aktuellen Zeile gesucht - also gweissermaßen "rundherum".
?reg.Ausdr.? sucht genauso, jedoch von der aktuellen Position
aus rückwärts.
Man kann die regulären Ausdrücke genauso wie die Zeilennummern zum
Adressieren von Textzeilen verwenden. Um beispielsweise die erste Zeile zu löschen,
in der das Wort "Festplatte" enthalten ist, genügt es, den Befehl
/Festplatte/d einzugeben.
| l | (list) Auflisten der adressierten Zeilen |
| n | (number) Auflisten der Zeilen mit Zeilennummern |
| p | (print) Auflisten der Zeilen (Voreinstellung, wenn Anweisung fehlt |
Für alle Anweisungen gibt es eine Voreinstellung (default) für die Zeilenadressierung, die dann genommen wird, wenn keine Zeilenadressierung vor der Anweisung erfolgt. Die Kommandos a, i und c werden, wie schon erwähnt, mit einer Zeile abgeschlossen, die nur einen Punkt enthält.
| Anweisung | default | Funktion |
|---|---|---|
| a | . | (append) Anhängen von Text an die adressierte Zeile |
| c | .,. | (change) Ersetzen der adressierten Zeilen durch neuen Text |
| d | .,. | (delete)Löschen der adressierten Zeilen |
| e Datei | (edit) Angegebene Datei laden | |
| f | (file) Dateinamen ausgeben | |
| f Datei | (file) Dateinamen festlegen(merken) | |
| g/ra/x | 1,$ | (global) Editoranweisung x für alle Zeilen ausführen, die den regulären Ausdruck ra erfüllen |
| g | (global) g kann auch an eine Anweisung angehängt werden; die Anweisung wird global ausgeführt. | |
| h | (help) Erklärung zur letzten Fehlermeldung (die nur aus '?' besteht) | |
| H | (Help) Help-Funktion auf Dauer einschalten | |
| i | . | (insert) Wie append, jedoch Einfügen vor der aktuellen Zeile |
| j | .,. | +1 (join) Zeilen aneinanderhängen |
| l | .,. | (list) Zeilen komplett auflisten |
| m Adr | .,. | (move) Zeilen hinter Zeile Adr verlagern n .,. (number) Zeilen mit Nummern anzeigen |
| p | .,. | (print) Zeilen anzeigen |
| P | (Prompt) Promptzeilen ein-/ausschalten | |
| q | (quit) Editorverlassen. ed warnt mit '?', wenn nicht gespeichert wurde | |
| Q | (Quit) Editor ohne Warnung verlassen (Text ist weg) | |
| r Datei | $ | (read) Text aus der angegebenen Datei einlesen (hinter die adress. Zeile) |
| s/ra/x/ | .,. | (substitute) Vom regulären Ausdruck abgedeckten String durch x ersetzen |
| t Adr | .,. | (transfer) Den adressierten Textbereich hinter die Zeile Adr kopieren |
| u | (undo) Letzte Anweisung zurücknehmen | |
| w | 1,$ | (write) Text auf Datei schreiben |
| w Datei | 1,$ | (write) Text auf Datei mit dem angegeben Namen schreiben |
| !Kdo | UNIX-Kommando Kdo ausführen und in den ed zurückkehren |
s/alter Text/neuer Text/
Es wird das erste Vorkommen des alten Textes in der Zeile durch den neuen Text ersetzt.
Zum Beispiel:
Diese Zeile enthält einen Tuppfehler
s/Tu/Ti/p
Diese Zeile enthält einen Tippfehler
Kommt der alte Text mehrfach in der Zeile vor, wird er nur einmal ersetzt. Um in der gesamten Zeile zu ersetzen, wird das g angehängt:
s/Tu/Ti/g
Will man eine Zeichenkette im gesamten Text ersetzen, wird dazu der gesamte Text (oder auch nur ein Bereich) adressiert:
1,$s/Tu/Ti/g
Achtung! Es werden u. U. auch Zeichenketten ersetzt, die gar nicht ersetzt werden sollen. Im o. g. Beispiel würde auch "Tulpe" zu "Tilpe". Weitere Möglichkeiten:
| /string/ | adressiert die nächste Zeile, die 'string' enthält (rückwärts suchen mit ?string?) |
| ^ | steht für den Zeilenbeginn. /^Meier/ adressiert Zeile, die mit "Meier" beginnt |
| $ | steht für das Zeilenende. /Meier$/ adressiert Zeile, die mit "Meier" endet. /^$/ adressiert die nächste Leerzeile (Achtung! Doppelbedeutung! Im Suchmuster eines reg. Ausdrucks Zeilenende, als Adresse im ed-Kommando Dateiende). |
| [] | definiert einen Buchstaben aus dem Bereich
in []. Beginnt der Bereich mit ^, wird nach einen Zeichen gesucht, das
nicht im Breich enthalten ist (Bei Dateinamen war dies das !-Zeichen). [ABC]: einer der Buchstaben A, B oder C [A-Z]: Großbuchstaben [A-Za-z]: alle Buchstaben [^0-9]: keine Ziffer |
| . | der Punkt steht für ein beliebiges Zeichen (wie ? in der Shell), |
| * | der Stern "*" steht für eine beliebige Folge des vorhergehenden
Zeichens (auch Null Zeichen!). a*: Leerstring oder beliebige Folge von a's aa*: eine beliebige Folge von a's (mindestens eines) [a-z]*: Leerstring oder eine beliebige Folge von Kleinbuchstaben [a-z][a-z]*: eine beliebige Folge von Kleinbuchstaben (mindestens einer) .*: jede beliebige Zeichenfolge |
| \ | hebt den Metazeichen-Charakter für das folgende Zeichen auf a* steht für Leerstring oder beliebige Folge von a's a\* steht für die Zeichenfolge "a*" |
| \( \) | Reguläre Ausdrücke können mit Klammern
gruppiert werden. Damit die Klammern nicht als Zeichenkette aufgefaßt werden,
muß ein \ davor stehen, also schreibt man in der Regel immer "\(" und "\)". \([A-Za-z]*\) gruppiert beispielsweise ein Wort aus beliebig vielen Buchstaben, wobei auch ein leeres Wort (0 Buchstaben) dazugehört. Soll das Wort mindestes einen Buchstaben enthalten, muß man \([A-Za-z][A-Za-z]*\) schreiben. Die Anwendung solcher Gruppen wird weiter unten gezeigt - es kann in den Editor-Befehlen nämlich Bezug auf die Gruppen genommen werden. |
| \i | Referenzieren des i-ten Klammerausdrucks (siehe Beispiele weiter unten) |
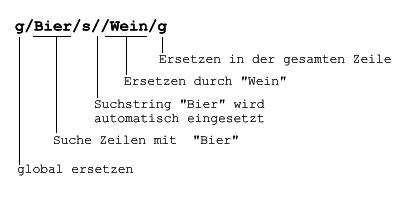
In den folgenden Beispielen wird von einer Telefonliste ausgegangen, die aus Namen, Vornamen und Telefonnummer besteht:
| 1,$p | |
| Anders Helga | 781 |
| Huber Karl | 123 |
| Meier Hans | 231 |
| Schulze Maria | 256 |
| Weber Klaus | 400 |
Die Telefonnummern sollen um dem Text "Tel.: " ergänzt werden. Dazu wird eine weiteres Feature der s-Anweisung verwendet. Auf den regulären Ausdruck kann durch \n Bezug genommen werden. Dabei ist n die Nummer der Gruppe (runde Klammern) im regulären Ausdruck, der den Suchstring definiert.
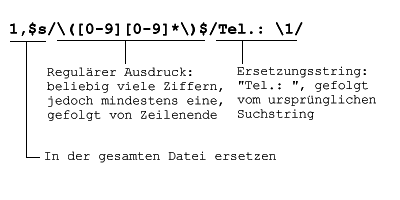
Das Ergebnis sieht dann so aus:
| Anders Helga | Tel.: 781 |
| Huber Karl | Tel.: 123 |
| Meier Hans | Tel.: 231 |
| Schulze Maria | Tel.: 256 |
| Weber Klaus | Tel.: 400 |
Jetzt sollen Nachname und Vorname vertauscht werden (beachten Sie die Leerzeichen zwischen den Gruppen)
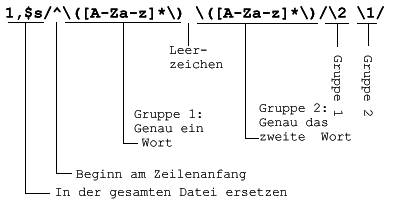
Das Ergebnis sieht dann so aus:
| Helga Anders | Tel.: 781 |
| Karl Huber | Tel.: 123 |
| Hans Meier | Tel.: 231 |
| Maria Schulze | Tel.: 256 |
| Klaus Weber | Tel.: 400 |
Zum Schluß werden die Telefonnummern aus der Liste entfernt:
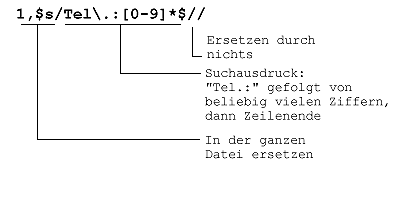
Das Ergebnis sieht dann so aus:
| Helga Anders |
| Karl Huber |
| Hans Meier |
| Maria Schulze |
| Klaus Weber |
Wegen der Angabe des regulären Ausdrucks in der Befehlszeile muß der reguläre Ausdruck in " " oder ' ' eingeschlossen werden, wenn er Leerzeichen oder Sonderzeichen enthält, die von der Shell ersetzt werden. Wurde keine Datei angegeben, liest grep von der Standardeingabe. Optionen:
| -q | (quiet) Nur Return-Wert zurückgeben. |
| -n | Zeilennummern mit ausgeben. |
| -c | Nur die Anzahl der Zeilen ausgeben, für die der reguläre Ausdruck erfüllt ist. |
| -l | Nur die Namen der Dateien ausgeben, in denen etwas gefunden wurde. |
| -i | Groß-/Kleinschreibung nicht unterscheiden. |
| -v | Alle Zeilen ausgeben, in denen der reguläre Ausdruck nicht erfüllt ist. |
Suchen nach allen Zeilen, die mit dem Wort "Beispiel" beginnen; Ausgabe der Zeilennummern: grep '^Beispiel' -n Vorlesung
Wichtig ist grep für den Systemverwalter, z. B. einen Login-Namen in der Benutzerdatei suchen (damit nicht derselbe Name zweimal verwendet wird):
grep "^Klaus:" /etc/passwd
Bei grep wird auch vielfach nur der Rückgabewert des Programms (nicht die Ausgabe!) verwendet. In Skript-Konstruktionen (siehe später) kann das beispielsweise so aussehen:
if grep -q "^Klaus:" /etc/passwd ; then .....
| -c | nur prüfen ob die Dateien sortiert sind |
| -u | reduziert mehrere identische Zeilen auf eine einzige (wie sort ... | uniq) |
| -d | lexikographisch sortieren (Buchstaben, Ziffern, Leerzeichen, Tabulatorzeichen) |
| -f | Groß-/Kleinschreibung ignorieren |
| -i | nichtdruckbare Zeichen ignorieren |
| -r | absteigend sortieren |
| -n | numerisch sortieren |
Beim Aufruf von sort können Sortierschlüssel angegeben werden, die festlegen, nach welchem Feld oder welchen Feldern sortiert wird. Als Feld wird dabei eine Zeichenkette betrachtet, die von Leerzeichen, Tabulator, etc. begrenzt ist. Die Sortierschlüssel sind folgendermaßen aufgebaut:
| +m[.n] | Beginn des Sortierbereichs. m Felder und n Zeichen überspringen - es wird also beim n+1. Zeichen im m+1. Feld begonnen (Voreinstellung für n: 0). |
| -m[.n] | Ende des Sortierbereichs. Nicht mehr dazu gehören alle Zeichen ab dem n. Zeichen (einschl. Trennzeichen) nach den m. Feld (Voreinstellung für n: 0). |
| +2 | UNIX ist ein einfaches Betriebssystem. |
| +3.2 | UNIX ist ein einfaches Betriebssystem. |
| +2 -3 | UNIX ist ein einfaches Betriebssystem. |
| -n | Die Standardausgabe wird unterdrückt (sinnvoll im Zusammenhang mit Pipes). |
| -e |
Es werden die auf die Option -e folgenden Anweisungen
für die Bearbeitung der Eingabedatei verwendet. Bei mehr als
einer Anweisung müssen die Anweisungen durch Semikolon voneinander
getrennt werden. Das Semikolon mußdabei ohne Leerzeichen direkt hinter
der Anweisung stehen! Die -e Option kann mehrfach angegeben werden. Um Fehlinterpretationen der Shell zu vermeiden, sollte die Editieranweisung grundsätzlich in Hochkomma oder Gänsefüßchen eingeschlossen werden. |
| -f | Wird diese Option angegeben, dann liest sed seine Editieranweisungen aus der angegebenen Datei. Die Anweisungen müssen entweder durch Semikolon getrennt werden oder jede Anweisung muß in einer eigenen Zeile stehen. Leerzeichen hinter einer Anweisung sind nicht erlaubt. Die Anweisungen dürfen nicht in Hochkommata eingeschlossen werden. Durch mehrfache Angabe der -f Option können mehrere Skriptdateien zugewiesen werden. |
sed kennt dieselben Anweisungen wie der interaktive Editor ed. Auch die Adressierung (Zeilennummern, reguläre Ausdrücke) erfolgt auf die gleiche Weise. Editieranweisungen haben die folgende Form:
[Adresse1 [,Adresse2 ] ] Funktion [Argumente]
Für jede Zeile der Eingabedatei werden alle Anweisungen ausgeführt. Durch Angabe einer Zeile (Adresse1) oder eines Zeilenbereichs (Adresse1, Adresse2) kann man deren Wirkung jedoch einschränken. Anstelle von Zeilennummern können auch reguläre Ausdrücke verwendet werden:
[/Muster/] Funktion [Argumente]
[/Muster1/ [/Muster2/]] Funktion [Argumente]
Im ersten Fall wird jede Zeile, die die Zeichenkette Muster enthält, von der Anweisung bearbeitet, im zweiten Fall alle Bereiche der Eingabedatei, die mit einer Zeile, die Muster1 enthält, beginnen und mit einer Zeile, die Muster2 enthält, enden.
Zusätzlich hat der sed noch weitere Funktionen (z.B. Test- und Sprungfunktionen, Klammerung, Wiederholungen) und er eignet sich daher besonders für Shell-Skripts. Interessant sind beim sed die Klammern:
Die folgende Tabelle faßt die sed-Kommandos knapp zusammen.
| a\ (append lines)
text | text wird nach der aktuellen Eingabezeile auf die Standardausgabe geschrieben. Besteht der text aus mehreren Zeilen, so muß das Fortsetzungszeichen \ am Zeilenende vor RETURN angegeben werden. |
| b [marke] (branch to label) | Es wird zu der marke (in der Form :marke angegeben) des sed-Skripts gesprungen und dort die Abarbeitung des Skripts fortgesetzt. Fehlt die Angabe der Marke, so wird an das Skriptende gesprungen, was bewirkt, daß eine neue Eingabezeile gelesen und das sed-Skript von Beginn an mit dieser neuen Eingabezeile wieder ausgeführt wird. |
| c \ (change lines)
text | Der Inhalt des Eingabepuffers wird durch text ersetzt. Besteht text aus mehreren Zeilen, so muß das Fortsetzungszeichen \ am Zeilenende vor RETURN angegeben werden. |
| d (delete lines) | Der Inhalt des Eingabepuffers wird gelöscht (nicht ausgegeben), und das sed-Skript wird sofort wieder von Beginn an mit dem Lesen einer neuen Eingabezeile gestartet. |
| D (Delete lines part of pattern space) | Der erste Teil des Eingabepuffers (bis zum ersten Zeilenende) wird gelöscht (nicht ausgegeben), und das sed-Skript wird sofort wieder von Beginn an mit dem restlichen Eingabepuffer gestartet. Pattern space ist der Eingabepuffer. |
| g (get contents of hold area) | Der Inhalt des Eingabepuffen wird durch den Inhalt des Haltepuffers (hold area) Überschrieben. |
| G (Get contents of hold area) | Der Inhalt des Haltepuffers wird am Ende des Eingabepuffers (mit Newline-Zeichen getrennt) angehängt. |
| h (hold pattern space) | Der Inhalt des Haltepuffers wird durch den Inhalt des Eingabepuffers überschrieben. |
| H (Hold pattern space) | Der Inhalt des Eingabepuffers wird am Ende des Haltepuffers (mit Newline-Zeichen getrennt) angehängt. |
| i\ (insert lines)
text | Der text wird vor der aktuellen Eingabezeile auf die Standardausgabe geschrieben. Besteht der text aus mehreren Zeilen, muß das Fortsetzungszeichen \ am Zeilenende vor RETURN angegeben werden. |
| l (list pattern space on the standard output) | Der Inhalt des Eingabepuffers wird auf die Standardausgabe geschrieben, wobei nicht druckbare Zeichen durch ihren ASCII-Wert (2-Ziffer) ausgegeben werden. Überlange Zeilen werden als mehrere einzelne Zeilen ausgegeben. |
| n (next line) | Der Eingabepuffer wird auf die Standardausgabe ausgegeben, dann wird die nächste Eingabezeile in den Eingabepuffer gelesen. |
| N (Next line) | Die nächste Eingabezeile wird an den Eingabepuffer (mit Newline-Zeichen getrennt) angehängt; die aktuelle Zeilennummer wird hierbei weitergezählt. |
| p (print) | Der Eingabepuffer wird auf die Standardausgabe ausgegeben. |
| P (Print first part of the pattem space) | Der erste Teil des Eingabepuffers (einschließlich des ersten Newline) wird auf die Standardausgabe ausgegeben. |
| q (quit) | Nach Ausgabe des Eingabepuffers (nicht bei Option -n) wird zum Skriptende gesprungen und die Skriptausführung beendet. |
| r datei (read the contents of a file) | Es wird die Datei datei gelesen und ihr Inhalt auf die Standardausgabe ausgegeben, bevor die nächste Eingabezeile gelesen wird. Zwischen r und datei muß genau ein Leerzeichen sein. |
| s/regulärer Ausdruck/text/[flags] (substitute) | Im Eingabepuffer werden die Textstücke, die durch den regulären Ausdruck
abgedeckt sind, durch den String text ersetzt. Anstelle des Trennzeichens / kann
jedes beliebige Zeichen verwendet werden.
Die flags legen fest, wie der Ersetzungsprozeß durchgeführt werden soll.Es kann folgendes angegeben werden:
|
| t [marke] (test substitutions): | Falls seit dem letzten Lesen einer Eingabezeile oder der Ausführung einer t-Funktion eine Ersetzung stattfand, dann wird zu der marke (in der Form :marke angegeben) des sed-Skripts gesprungen und dort die Abarbeitung des Skripts fortgesetzt; im anderen Fall hat die Angabe dieser Funktion keine Auswirkung. Fehlt die Angabe der Marke, so wird an das Ende des Skripts gesprungen. |
| w datei (write to a file) | Es wird der Eingabepuffer an das Ende der Datei datei geschrieben. Zwischen w und datei muß genau ein Leerzeichen sein. |
| x (exchange) | Der Inhalt des Eingabepuffers wird mit dem Inhalt des Haltepuffers vertauscht. |
| y/string1/string2/ | Im Eingabepuffer werden alle Zeichen, die in string1 vorkommen, durch die an gleicher Stelle in string2 stehenden Zeichen ersetzt. string1 und string2 müssen gleich lang sein. |
| !funktion | Die angegebene Funktion (oder Gruppe von Funktionen bei Klammerung mit {}) wird nur für Zeilen ausgeführt, für die die angegebene Adreßangabe nicht zutrifft. |
| :marke | Definiert eine Sprungmarke für die Funktionen b und t. |
| " | Schreibt die aktuelle Zeilennummer als eigene Zeile auf die Standardausgabe. |
| {...} | Klammert eine Gruppe von Funktionen, die nur ausgeführt werden, wenn der Eingabepuffer gefüllt ist. |
| # | Dieses Zeichen leitet, wenn es als erstes Zeichen in einer Zeile angegeben wird, mit einer Ausnahme einen Kommentar ein. Die Ausnahme ist, wenn direkt nach # das Zeichen n angegeben wird; in diesem Fall wird die automatische Ausgabe, wie bei der Kommandozeilen-Option -n, ausgeschaltet. Der Rest der Zeile nach #n wird ebenfalls ignoriert. Eine Skript-Datei muß mindestens eine Nicht-Kommentarzeile enthalten. Eine leere Funktion wird ignoriert. |
 Zum Inhaltsverzeichnis Zum Inhaltsverzeichnis |
 Zum nächsten Abschnitt Zum nächsten Abschnitt |